Introduction
Classifiers are algorithms used by computers to classify data into a discrete class . For example a classifier can be used to recognize a human face in an image, every time you use your credit card, your credit card company may be running a Fraud detection algorithm using the information to determine if it is you or someone else. This post will go over one of the most straightforward yet powerful classifiers called Nearest Neighbors and K- Nearest Neighbors.
We will review the classic Iris dataset, the Nearest Neighbors algorithm and K-Nearest Neighbors algorithm. We then discuss how to select K using cross validation. This post is for beginners, the only math you will need is how to calculate the distance between two points. This post only scratches the surface but its a good starting point for beginner and will give you an overview of using machine learning for classification.
How we Use the Data
Let’s go over a the classic Iris dataset , a simple dataset for classification. Figure 1 shows three types of Iris Flowers Iris Setosa , Iris Versicolor and Iris Virginic.

There are two parts to the dataset, the labels and features, lets review the labels.
The Label
The variable y is used to represent the actual class of each object ; for the case of the Iris data set the variable y represents the Species of Iris flower . For example y=0 for Iris Setosa, y=1 for Iris Versicolor and y=2 for Iris Virginica. This is show in Figure 2:

Features
The main assumption of classification is different classes can be distinguished by different features. A feature is essentially a measurement, we place these measurements in a feature vector denoted with an x . Lets look at the Iris flowers, we have Sepals and Peddles , the assumption is each species of Flower have a different measurement of there Sepals and Peddles . For each flower we place each measurement into a vector. For Sepal we have the width and length as shown in Figure 3:
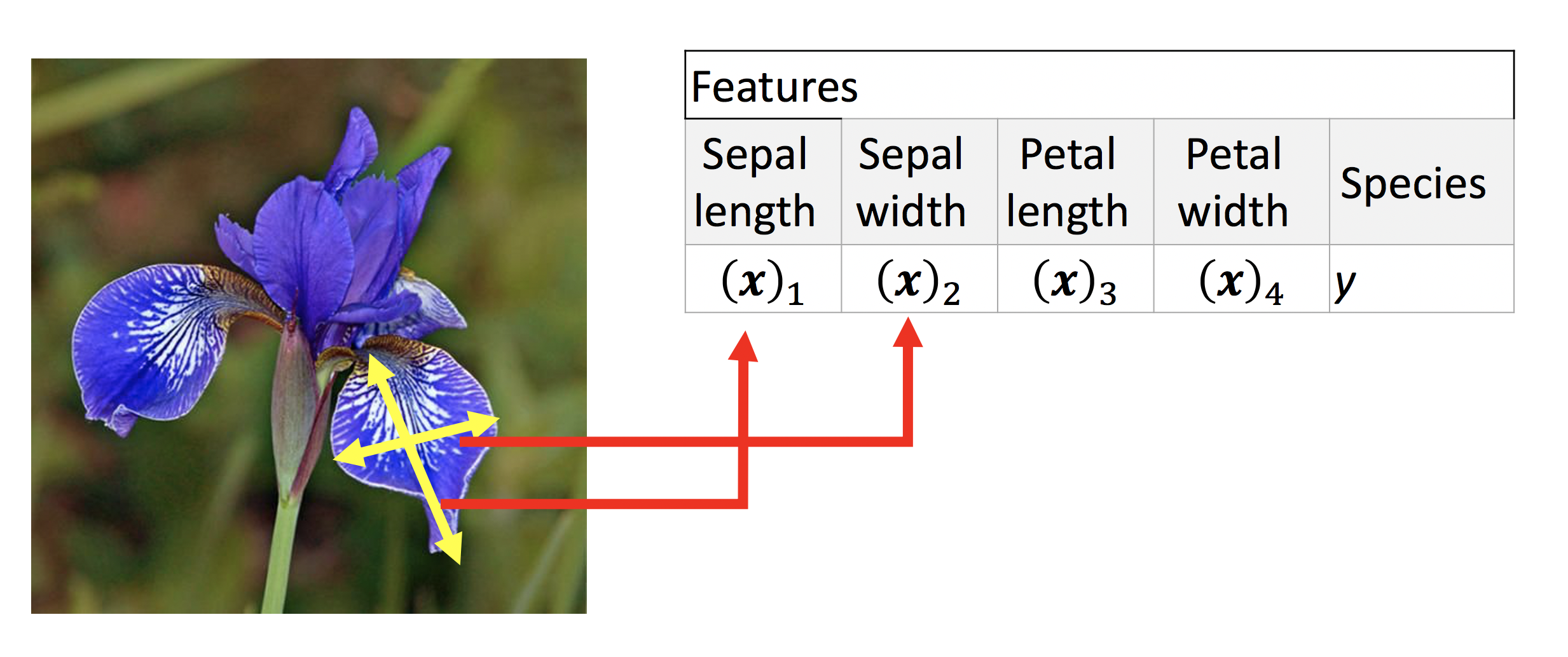
The first two elements of the vector are denoted by (x)1 and (x)2 respectively. We have a similar image for Petal length and Petal width:

The features x and the label y will now be used to classify a sample without a label.
The Dataset
The dataset is a labeled set of examples, we use the variable n to represent each sample, each feature vector xn has its own label yn we can see this in Figure 5. We have 6 samples the class is denoted by the variable y. It is helpful to use colors to help distinguish between each class as shown in figure 5 each class is directly above the feature vector.

It is helpful to plot the different feature vector samples as points on the number line and over lay the class as a color. This is shown in Figure 6, where we have three samples x1, x2 and x3 on points three, one and zero respectively.

In a similar manner we can also plot the feature vectors on the 2-D cartesian plane, overlaying the class color over the datapoint. This is shown in Figure 7 for three feature vectors x1, x2, and x3 . The vertical access (x)1 represents the first component and the horizontal axis (x)2 represents the second component. The class color is overlaid over the datapoint.
We can plot the features and samples in the Iris dataset, lets select two of the four different features and plot the different flowers on the cartesian plane. This is shown in figure 7 where we plot the sepal length and sepal width in cm.

We see the Blue points representing Iris Sentosa are relatively separate from the green and red points representing Iris Versicolor and Iris Virginica. We can even add an additional feature . We can plot more dimensions, let’s see what happens if we add an additional feature and plot the samples. This is shown in Figure 8, we have Sepal width, Sepal length and Petal length with the class color overlaid over the samples.
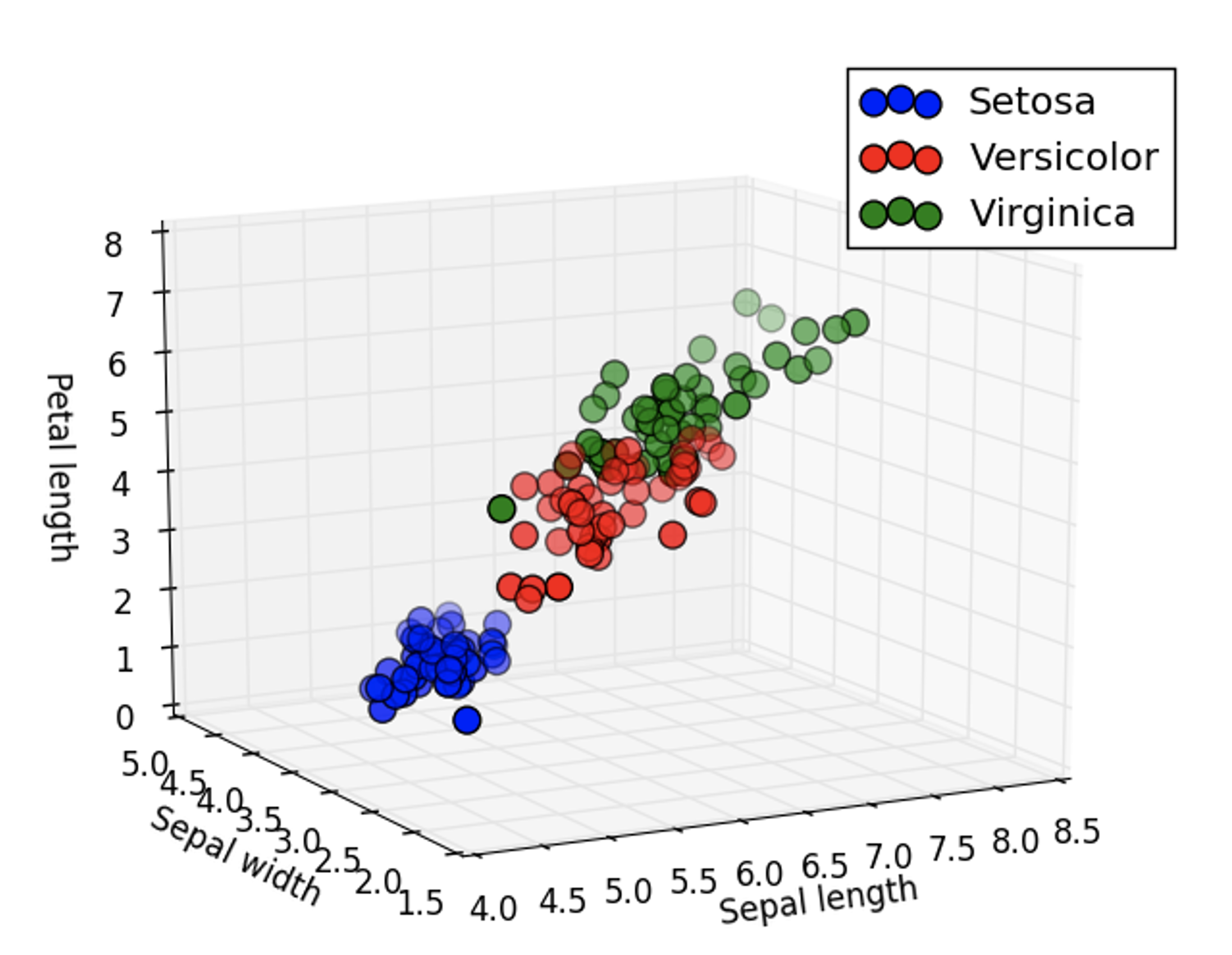
We can see that the Iris Versicolor and Iris Virginica samples appear more separated in three dimensions. We will now discuss how to use this dataset to classify and unknown sample.
Nearest Neighbors Algorithm
Consider the case where we have the features x from some unknown sample , and we would like to “guess” or estimate what class it belongs to. Consider figure 8, we have features from two classes we denote these as class red y=0 and class blue y= 1 respectively. These can be samples from the Iris data set. Now we have an unknown sample in black we would like to estimate this class we will denote this estimate with 
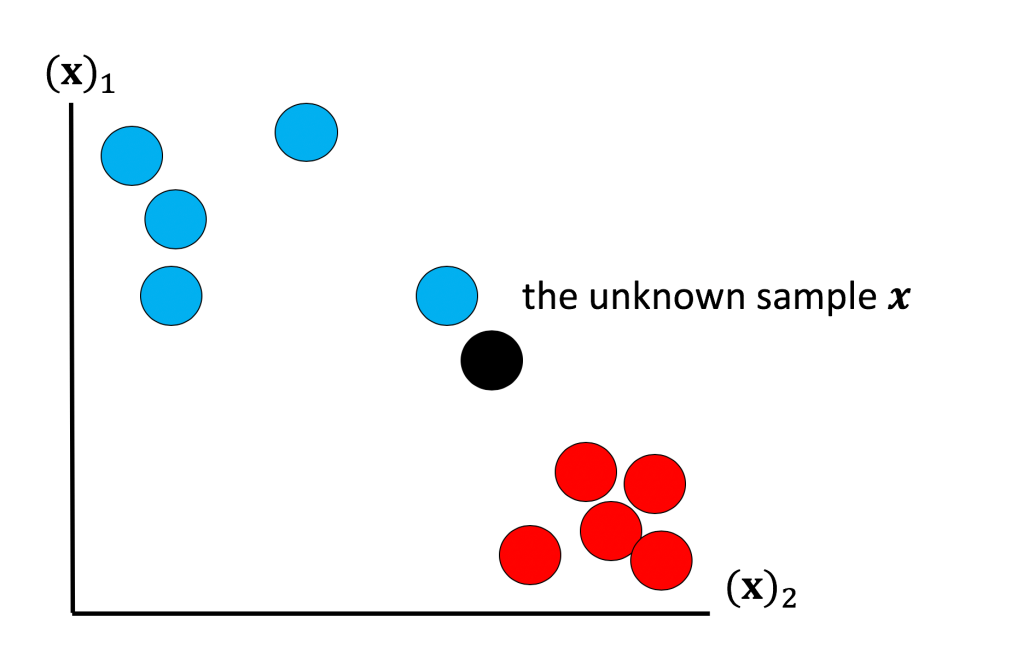
How would you classify this unknown sample ? Intuitively one way is to determine the near sample, and assign are unknown sample to the same class. In this case the blue sample is nearest and we would classify the unknown sample as blue. This is exactly how Nearest Neighbors work. We simply calculate the euclidean distance denoted by d(x1 , x2) from the nearest point. An example using two dimensions is show in figure 9 with two vectors x1 and x2 :
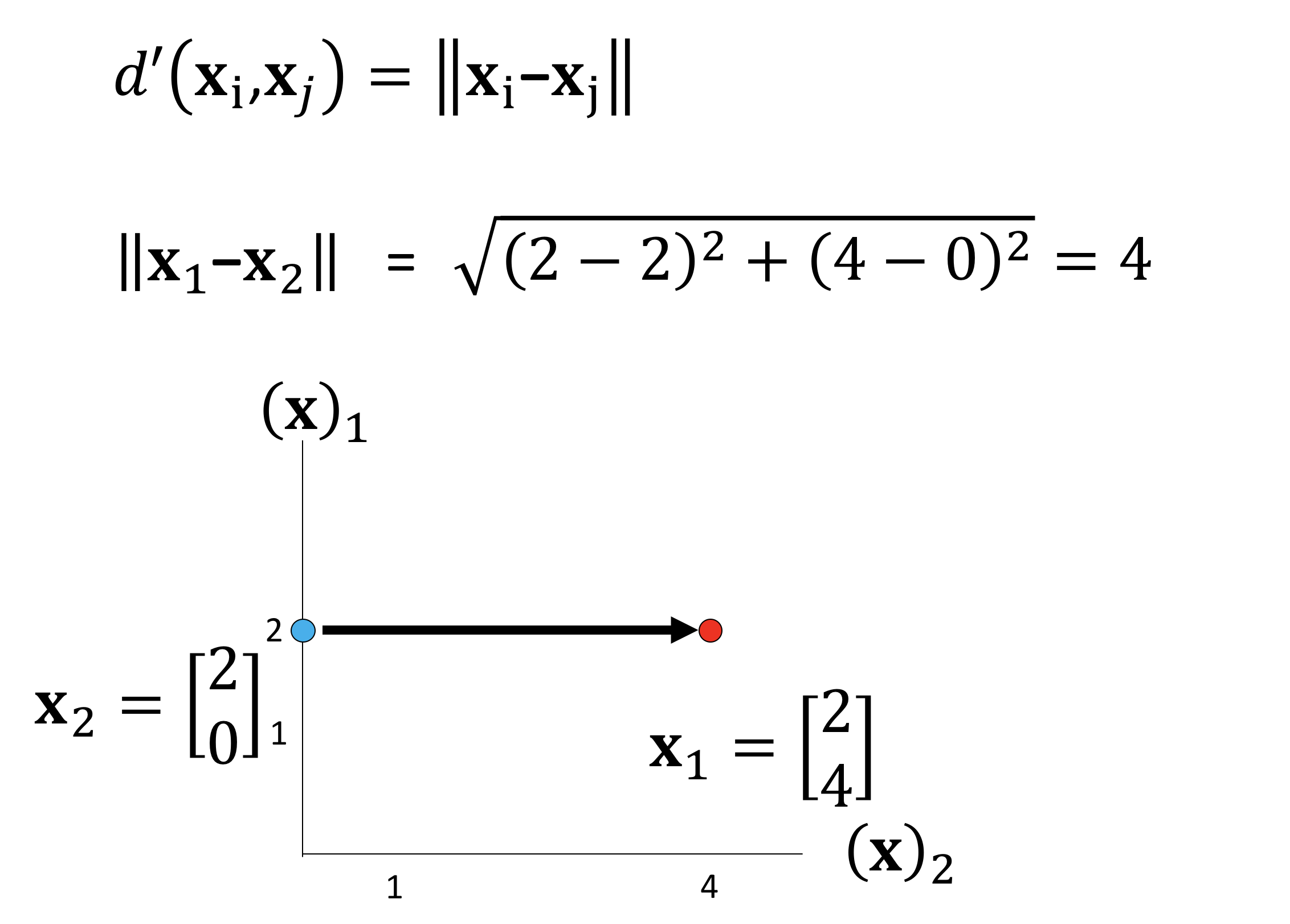
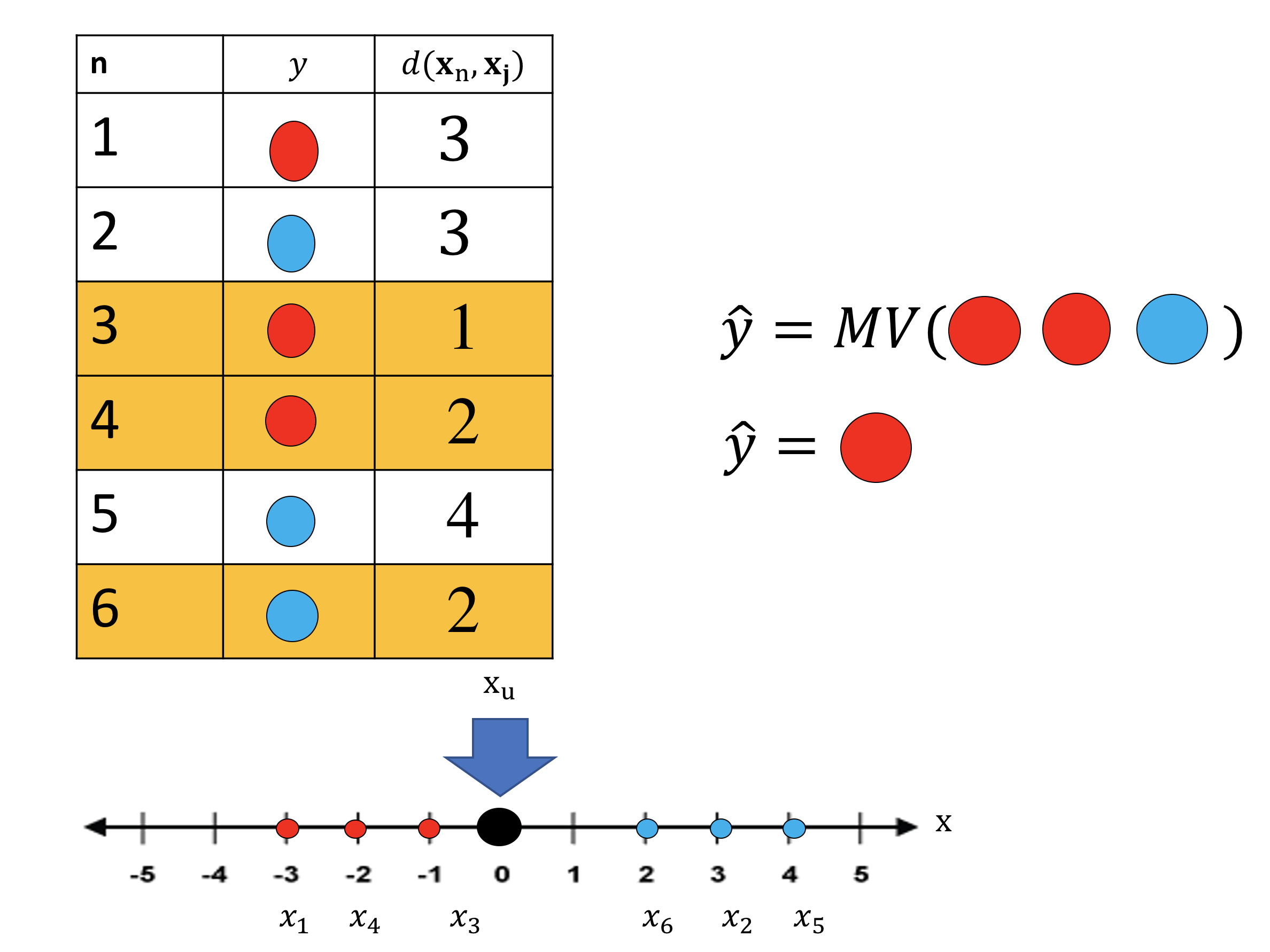
Let’s do a full-example in one dimension, consider the following samples in Figure 10. We have 5 samples on the x axis, with the class color overlaid above the points. We have the sample xu, we would like to determine the class of this sample. There is also a table above , the first column represents the sample number, the second column is the class of that sample, the third column represents the distance of that particular sample from xu.
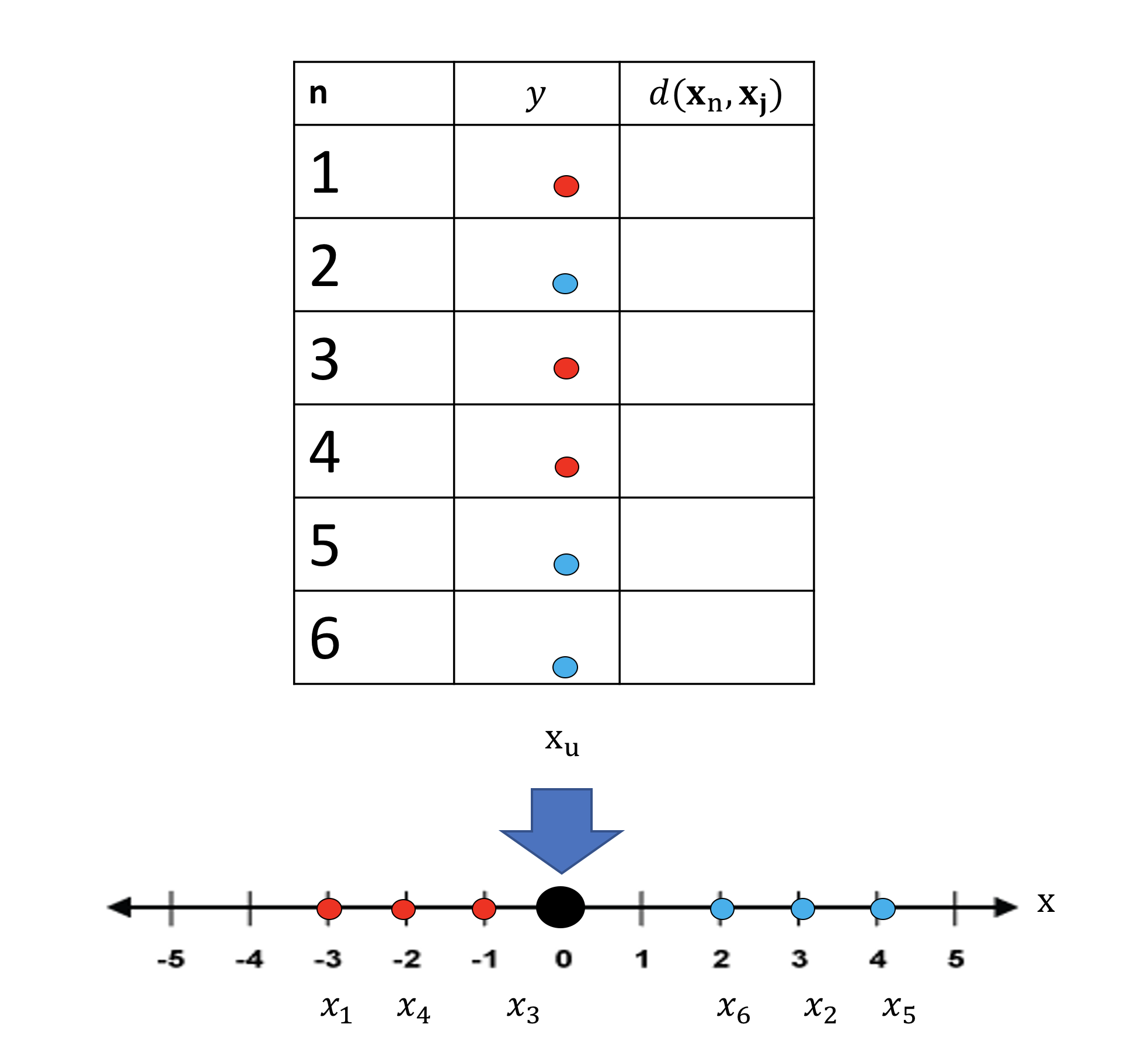
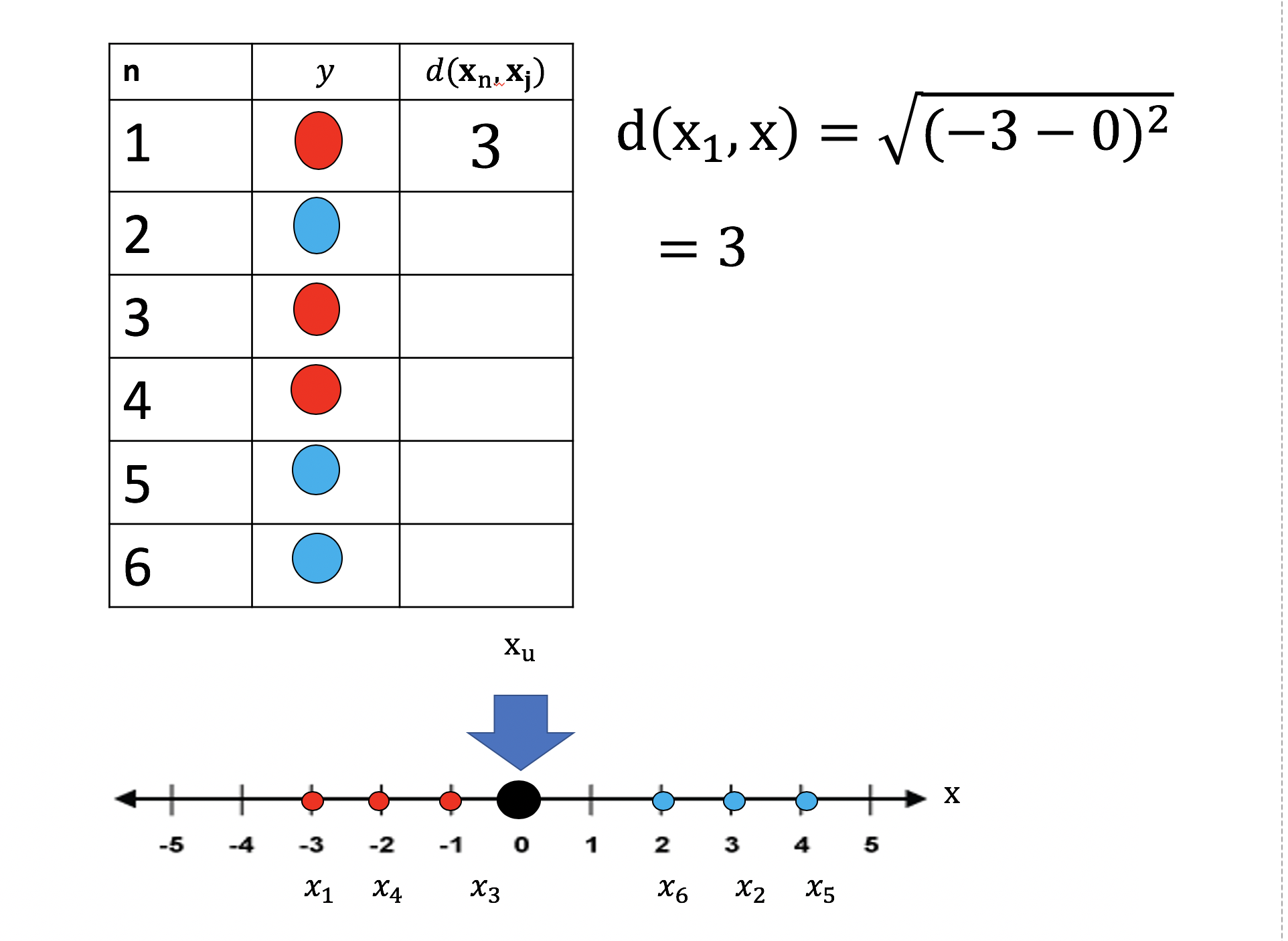
We can calculate the distance between x1 and xu , the distance is 3 . We then fill out the value in the table as shown in figure 11:
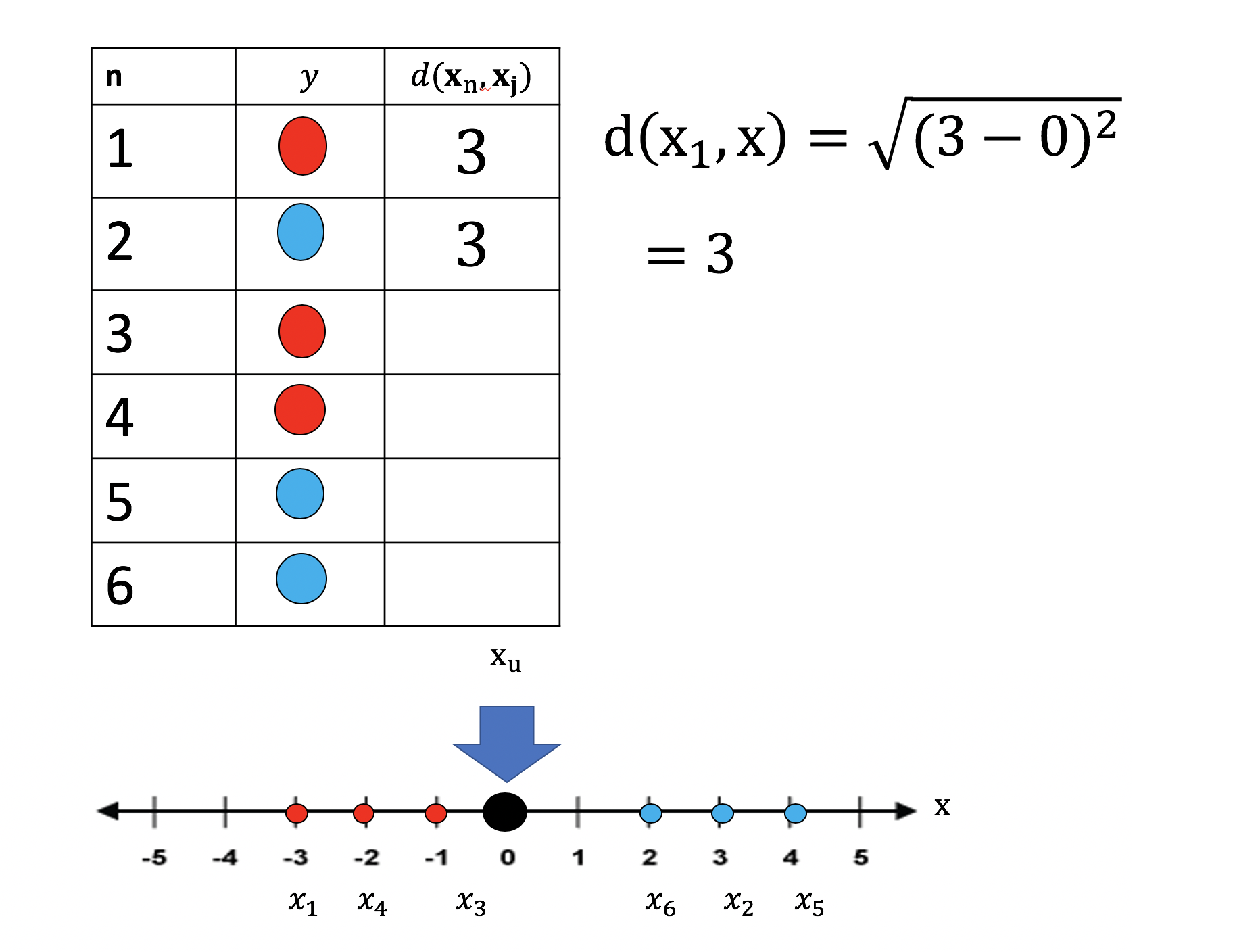
Let’s do one more example, this time we use the second sample and calculate the distance between x2 and xu . We fill out the table as shown in figure 12
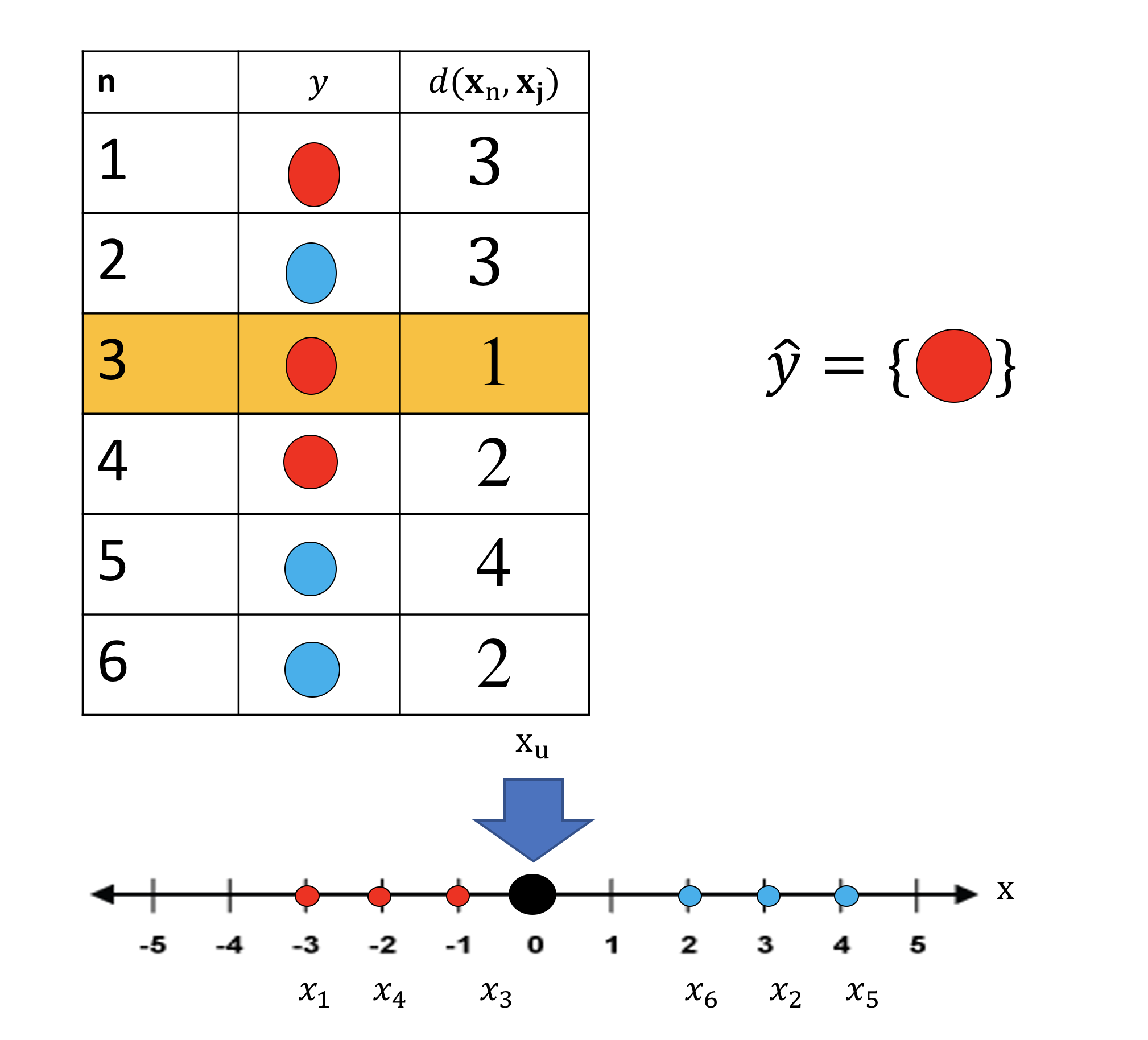
We calculate the distance between xu and the rest of the samples, we then select the class to be the same as the sample with the least distance from the rest. This is shown in figure 13 where the distances for each sample is shown in the third row. The class of the unknown sample is the same as the sample with the smallest distance. This is shown in figure 13 the nearest sample x3 is highlighted in orange ,we assign the sample the same class, in this case the red class i.e
One problem with Nearest Neighbors is if the dataset has a large number of samples, we would have to calculate the distance between each sample. In this case we only have six samples but datasets can have millions of samples.
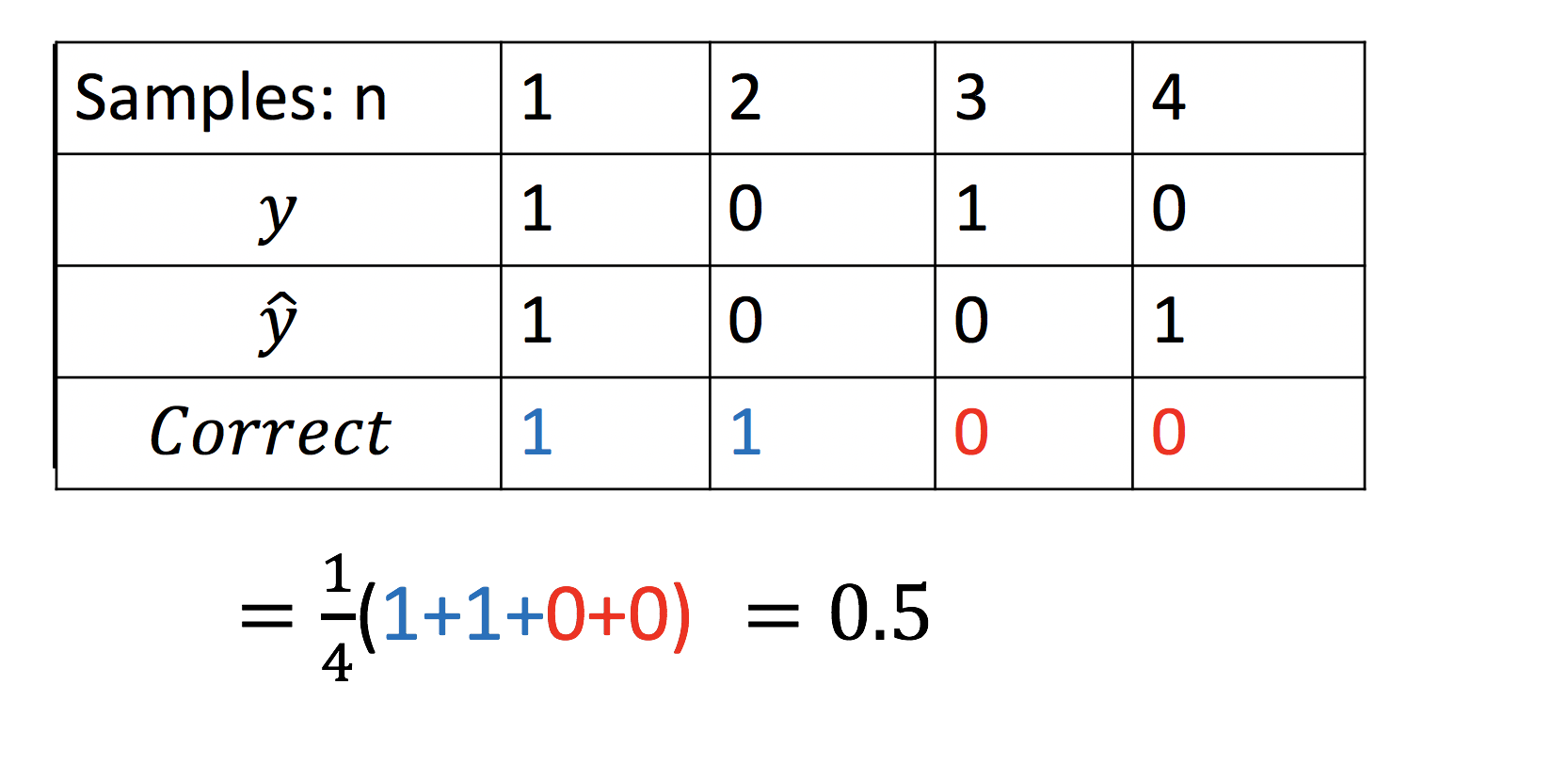
To determine the accuracy of the algorithm we determine the average number of times the estimated class of each sample equals the actual class of the sample. An example is shown in Figure 14, each column represents a different sample. The first row represents the sample number, the second row represents the actual class and the third row represents the predicted class. The final row equals one if the sample is classified correctly or zero otherwise . Finally we simply determine the average accuracy by determine the number of correctly classified samples. We convert the number to an average by dividing by the total number of samples.
K-Nearest Neighbors
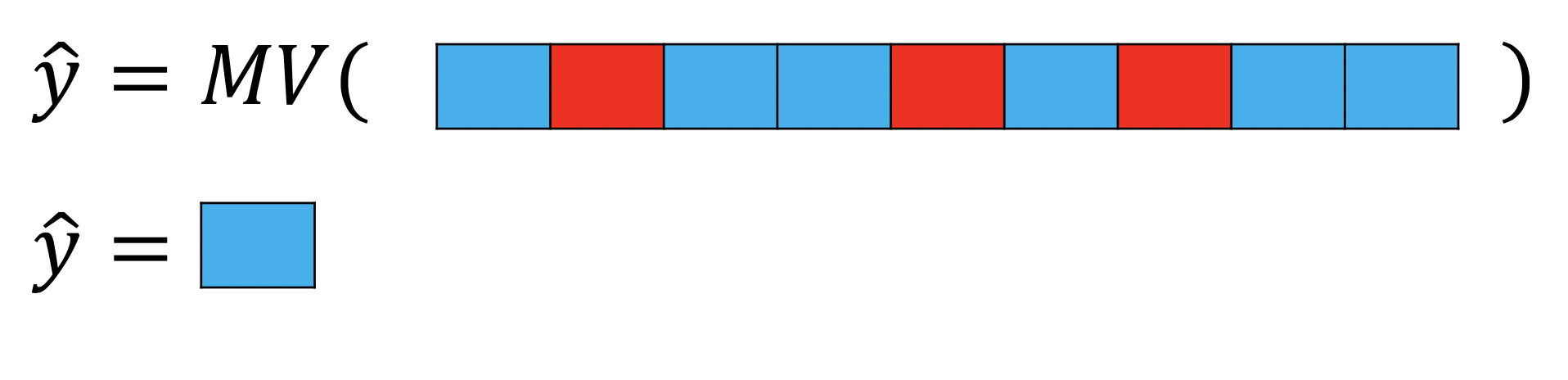
Now let us discuss K-Nearest Neighbors , but before we do lets discuss the Majority Vote function. This function simply outputs the class with the most number of occurrences. We can see an example in figure 15a we have the majority vote function denoted by MV, in the parentheses there are several samples of different classes. The output of the function is simply the class with the most number of samples . In this case there are more blue samples so the output is class blue.
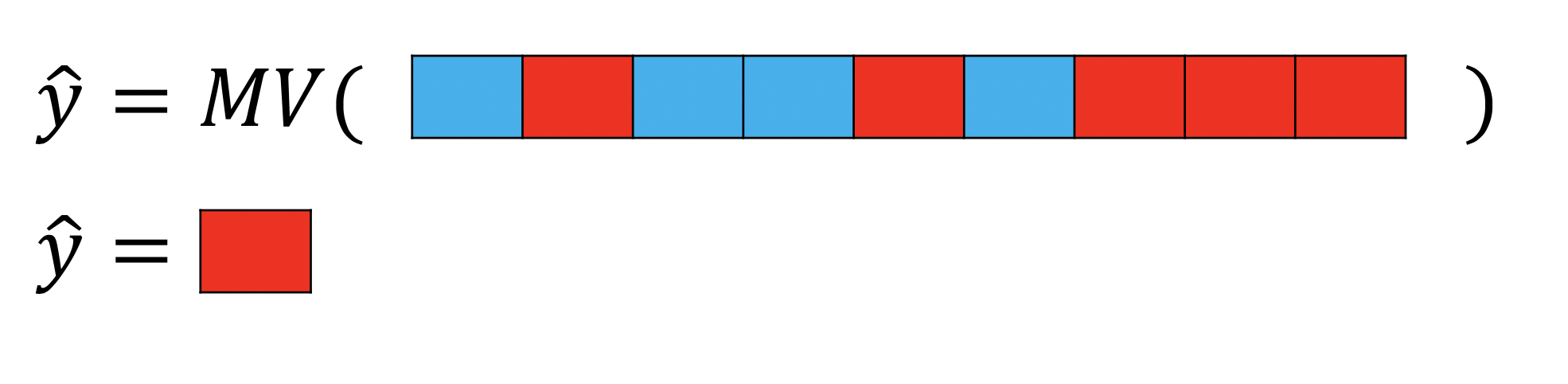
A second example is shown in figure 15b, in this case there are 5 red samples and 4 blue samples, as a result the output of the majority vote function is the class red.
In the K-Nearest Neighbors algorithm we simply find the class of the K nearest samples and apply the majority vote function. Figure 16 shows an example of K=3 . We select the three nearest samples 3,4 and 6 highlighted in yellow. We take the class of these samples and apply the majority vote function. The output
The term K is known as a hyperparameter, and is determined using cross validation . Cross validation works by splitting up our data into two subsets.
Cross-Validation
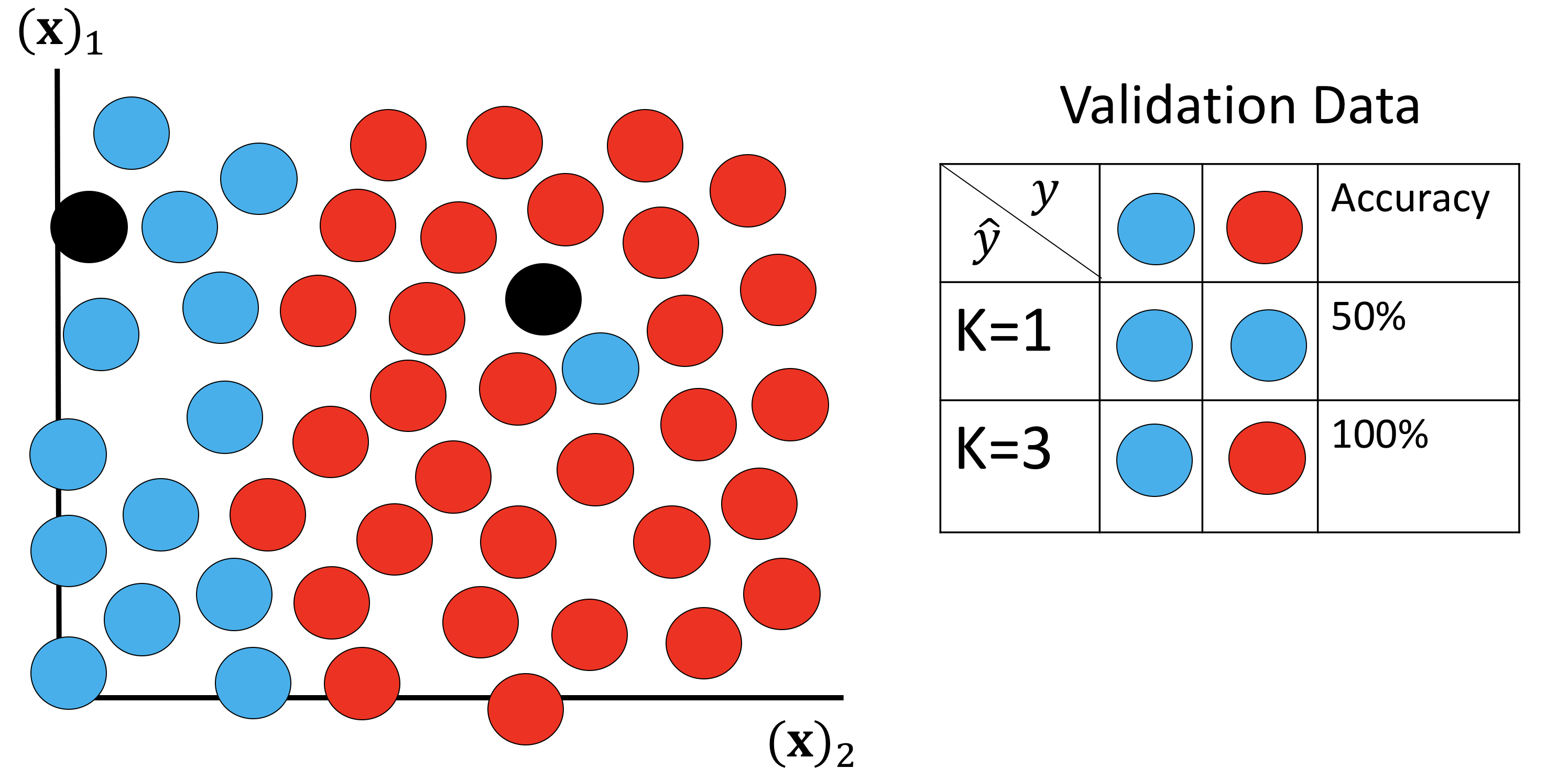
In order to determine the value of K we use Cross-Validation, we split up the dataset into two parts one to train the algorithm this is called the training dataset, in this case the dataset to find the Nearest Neighbors. The second set is called the validation set, we calculate the accuracy and select the value of K with the highest accuracy. This is shown in figure 17 where the two samples are used for validation data, the rest of the samples are used for training data.
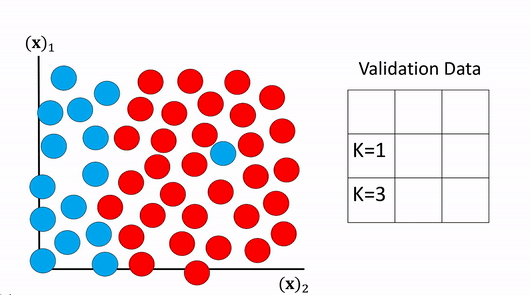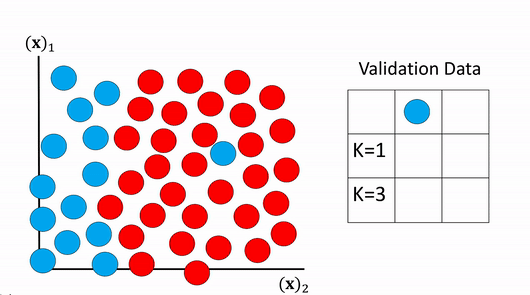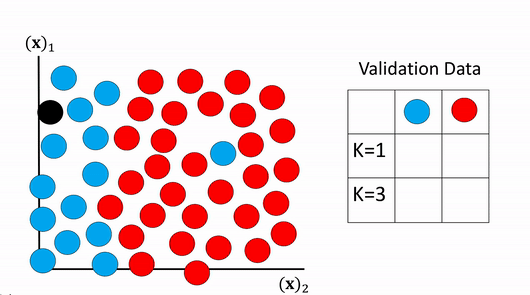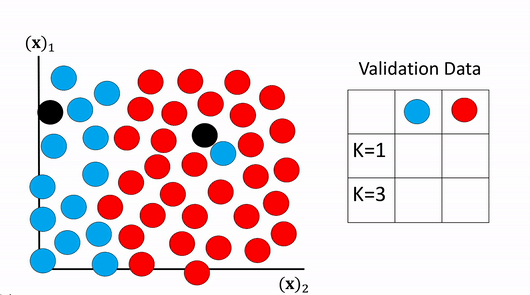
We then perform classification on the validation data and choose the value of K that has the best accuracy. This is shown in figure 18, examining the table on the right the first row contains the actual class value. The second row shows the predicted values using K equals one the accuracy is fifty percent . The second row shows the predicted value for K equals three the accuracy is one hundred percent. Therefor we select the value of K to be 3 as it had the highest accuracy.
In this post we reviewed K-Nearest Neighbors for classification, we reviewed the classic Iris dataset, the Nearest Neighbors algorithm and K nearest Neighbors algorithm. We then discussed how to select K using cross validation. This post only scratched the surface you can select different distance metrics , evaluation metrics and there are lots of classification algorithms.

Leave a comment